
东汉末年
评估ChatGPT和大语言模型的22篇论文
2023-03-21 16:23:39
整理自 https://github.com/KSESEU/LLMPapers
公开数据集评估交互式LLM的框架
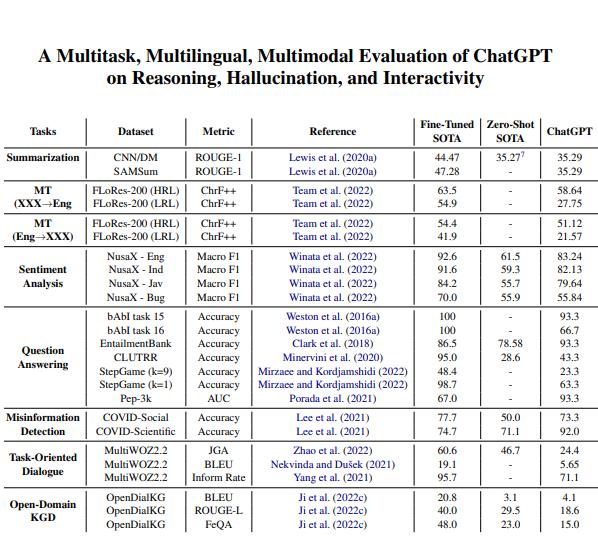
香港科技大学数据集框架
ChatGPT/3.5 不同任务下性能报告
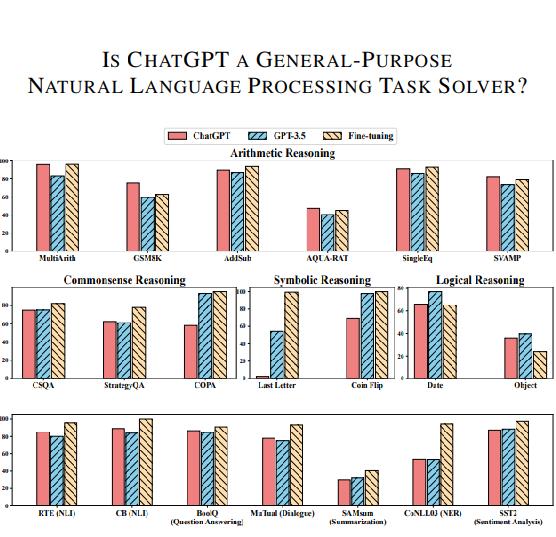
南洋理工斯坦福
ChatGPT与传统问答知识图谱比较
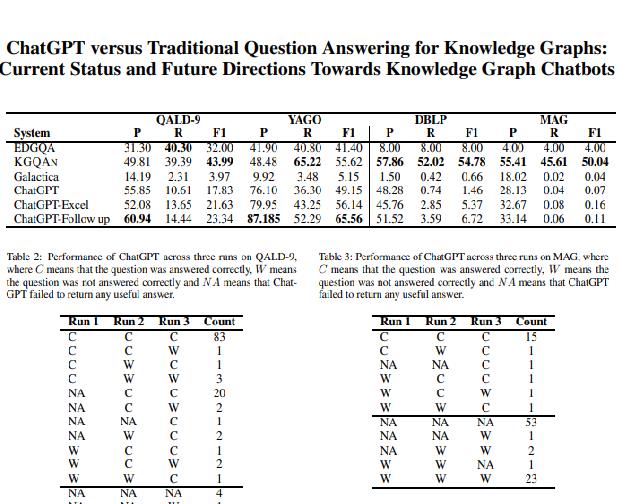
问答系统知识图谱
ChatGPT的数学能力
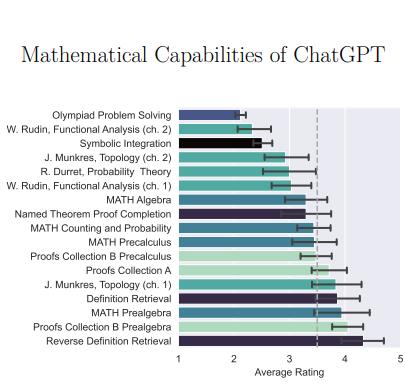
牛津大学剑桥大学
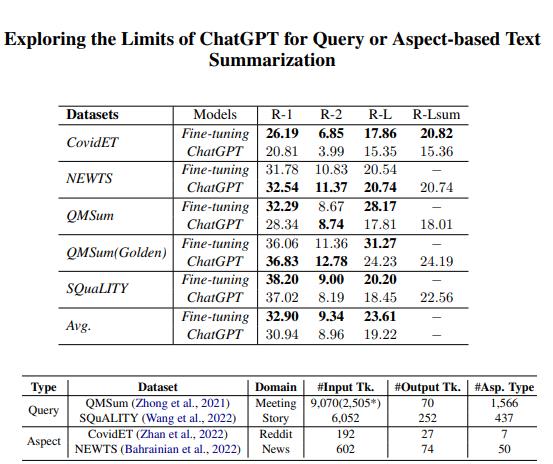
ChatGPT对基于查询的文本摘要
Microsoft
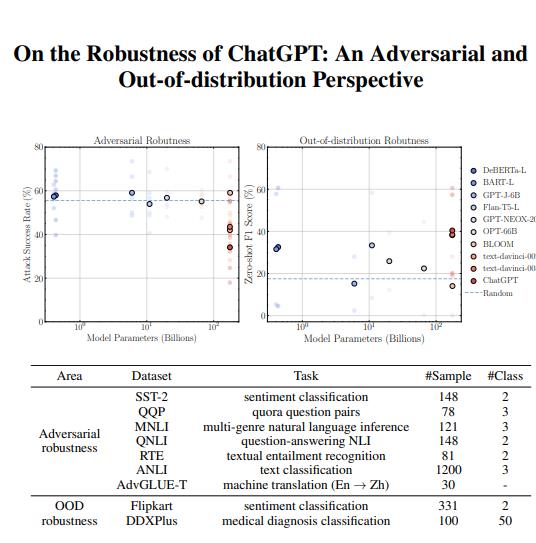
ChatGPT鲁棒性和泛化能力分析
miscrosoft
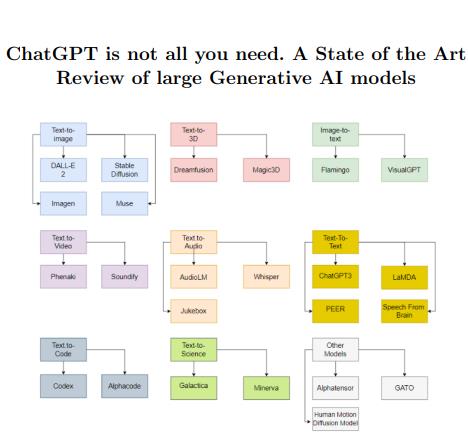
生成模型领域里ChatGPT不是一切
模型类别分析
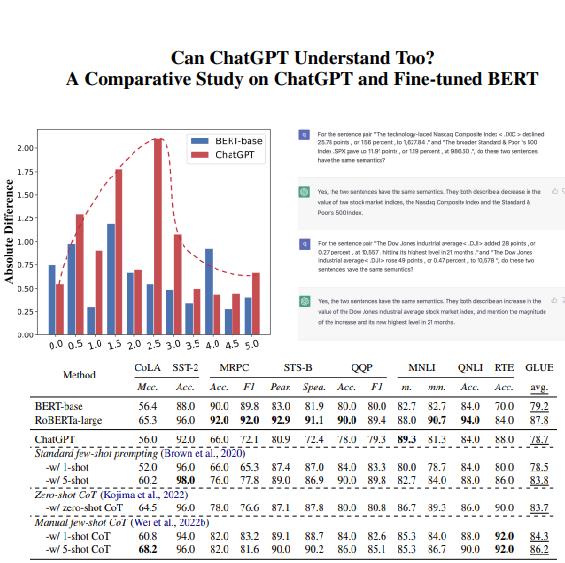
对比ChatGPT和微调的BERT
京东武汉大学悉尼大学
评估ChatGPT回答复杂问题的能力
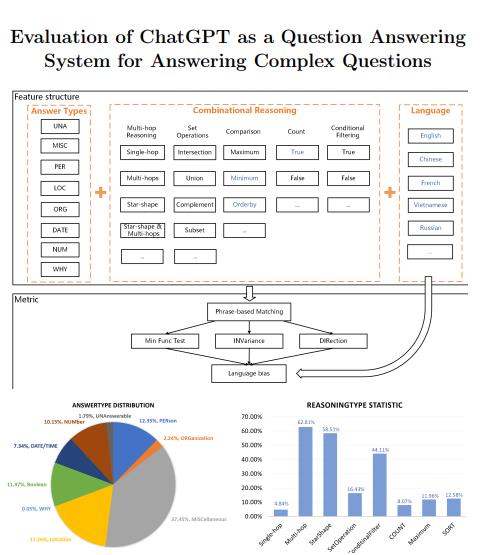
东南大学
语言模型的整体评价

2022斯坦福HAI
评估语言大模型的文本转SQL能力

剑桥大学
视觉语言模型是常识知识库吗
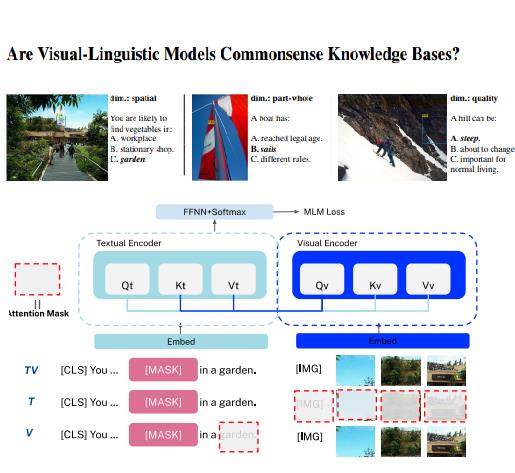
Stuttgart
心理学角度评估大模型GPT3
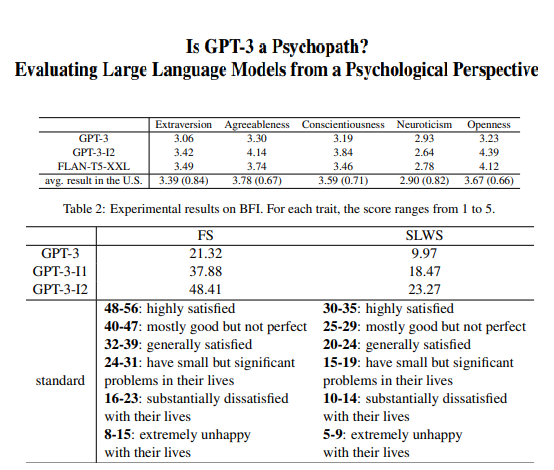
阿里巴巴
基于多语言模型地缘差异常识探索

加州大学
ROBUSTLR:推理机逻辑鲁棒性基准
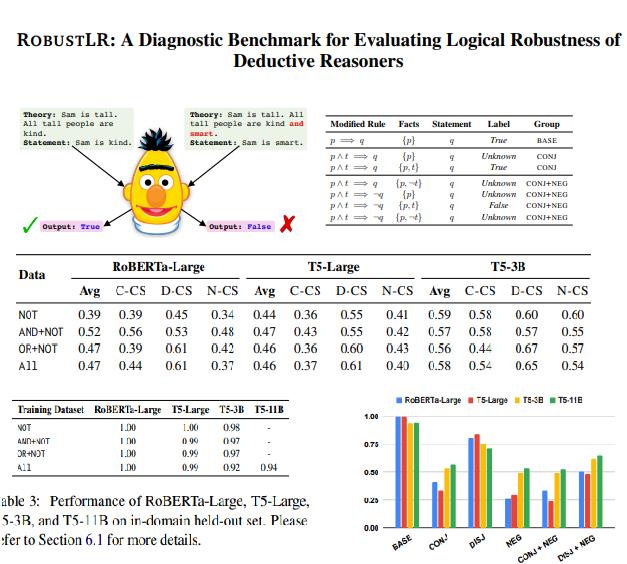
南加州大学
评估大语言模型生成代码
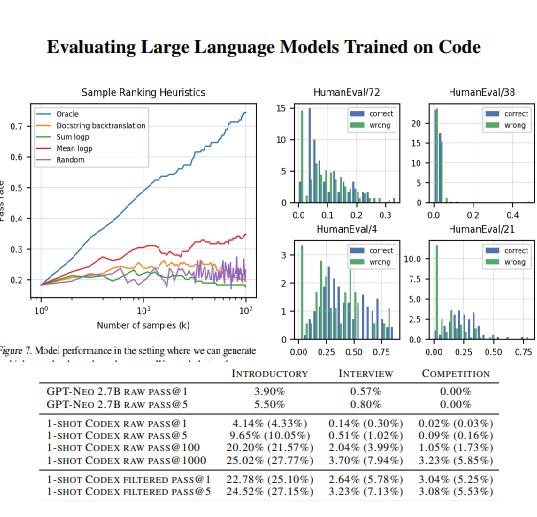
openai
GLGE:新的通用语言生成评估基准
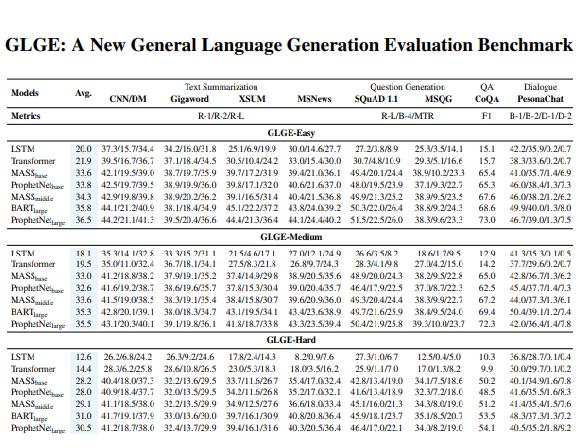
miscrosoft
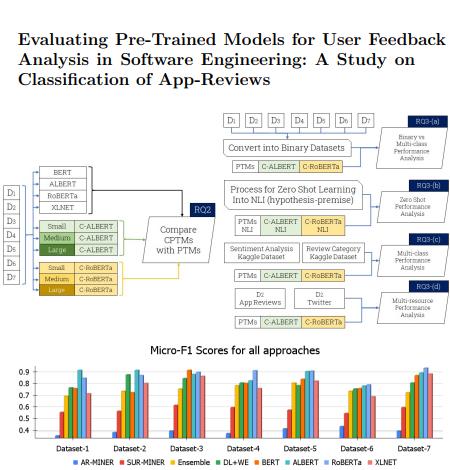
评估分析用户反馈的预训练模型
语言模型是否执行可归纳常识推理

南加州大学
RICA:基于常识公理评估推理能力

南加州大学
评估文本生成能力
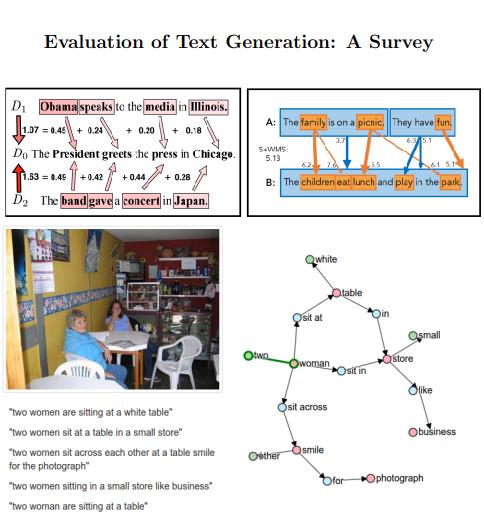
meta
神经语言生成:公式、方法和评估

Michigan
BERTScore:评估BERT文本生成
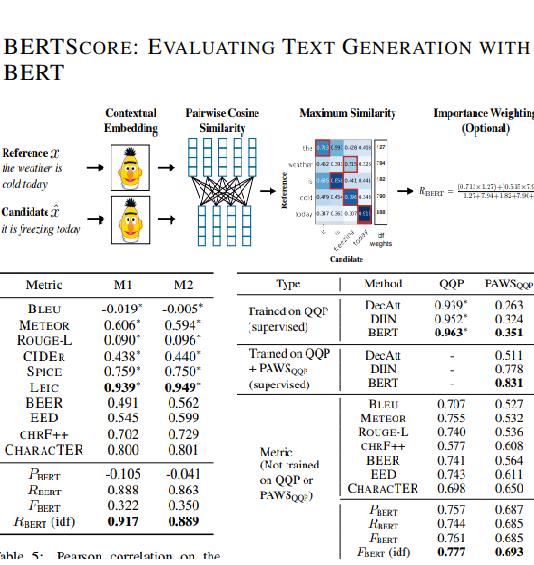
康奈尔大学
Comments
No comments yet, be the first to comment